![]()
![]()
![]()
![]()
![]()
WTX provides a set of requests to attach tools to or detach tools from the target server. These requests start and terminate communication with the target server. Requests are also available to lock and unlock other users' access to the target server. WTX and WDB messages can also be logged to files on user demand.
The protocol provides a standard set of symbolic debugging facilities. WTX supports the following primitives:
These primitives form the basis of more complicated debugging facilities such as "continue to return," or "step over." Such commands are provided by CrossWind, the Tornado debugger (see the Tornado User's Guide).
Those commands can be used in task mode (debugging a task) or in system mode (the kernel itself is suspended).
Binding to a target server is mediated by the Tornado registry, also known as the WTX registry (wtxregd), which provides and maintains a database of all executing target servers and their remote procedure call (RPC) IDs. WTX service calls exist to look up target server information kept in this database.
There is also a WTX request to attach a tool to a target server. The act of attaching allows the tool to provide information about itself. In addition, attached tools can query the target server for a list of other attached tools.
WTX-based tools can read, write, move, and otherwise manipulate target memory. WTX_MEM_ALLOC and WTX_MEM_FREE operate on the portion of target memory managed by the target server. All other WTX memory requests operate on any valid memory location on the target.
WTX_MEM_READ can be used to transfer data from the target to the host. There are no restrictions on the size of a transfer, but be aware that the time required to fulfill a large request depends on the speed of the host-target link. When transferring complex data structures, use WTX_GOPHER_EVAL, which is discussed in 4.3.11 Gopher Support.
WTX-based tools can request the disassembly of a target memory area with WTX_MEM_DISASSEMBLE, which can operate on any valid memory location on the target. The output is a string representing the assembly instructions stored in the given area. The disassembly is done by the target server using the CPU vendor's instruction mnemonics. The output of this facility matches the CPU vendor's documentation, which the disassembly produced by GDB may not.
The object-module loader allows the target server to load and unload relocatable or fully linked object modules to the target. Modules may be loaded from any tool. The object-module formats (OMFs) supported depend on what OMF readers are available to the target server. See installDir/host/resource/target/architecturedb for a list of the OMF readers available on your host.
The load operation can be synchronous (the tool waits for completion) or asynchronous (the tool checks for load completion, but can continue with other operations, including cancelling the submitted load request).
The loader adds all symbols defined by an object module to a symbol table managed by the target server. There is only one symbol table that is shared by all tools; thus a module loaded from one tool is visible from another.
The loader fully supports C++ modules and the symbol table records all symbols in their mangled form. The loader also supports text section protection if the optional product VxVMI is included on the target.
If some symbols are undefined during the link stage, the object module is not rejected. A partial link is performed, and the code can be utilized as long as all undefined references are avoided. WTX_OBJ_MODULE_LOAD returns a list of undefined symbols to inform the tool of all missing references.
The target server retains module information and WTX has service calls to get information on segment addresses, size, and so on.
The target server provides symbol-table management for the target. The symbol table holds all the target symbols, and service calls exist for adding, deleting, and looking up symbols. The symbol table is hashed for higher performance. There is only one symbol table; thus every tool sees all symbols.
Because I/O requirements during development may exceed the facilities available to the target, WTX provides virtual input and output (VIO) for the target. On the host, channels can be associated with a variety of devices (displays, files, streams, and so on). These act as input and output devices associated with the target.
Virtual I/O requires that the target configuration include the WDB agent and a virtual I/O device driver. Once installed, the virtual I/O driver provides standard I/O system access to the virtual I/O facility.
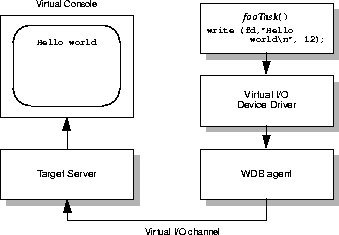
In Figure 4-4, a task on the target writes a buffer containing "Hello world" to a previously opened virtual I/O device. The buffer is transferred to the target server by the virtual I/O device driver and displayed in a host window.
A target task creates a virtual I/O channel by calling open( ) on a virtual I/O device. A bi-directional virtual I/O channel referenced by a unique number is attached to the file descriptor returned by open( ). This unique VIO channel number is then used during all read( ) and write( ) transactions mediated by the target server. The target server manages redirection of the VIO data to the appropriate device or tool.
The Target Server File System (TSFS) is based on Virtual IO. For more information on TSFS, see the VxWorks Programmer's Guide: Local File Systems.
Host tools must be notified of events occurring on the target and must know about certain actions performed by other tools. WTX meets this requirement by providing a register of events. Tools register to receive notification of particular events or event types. When an event occurs, it generates an event string which is sent to the target server. The target server forwards the string to the tools that have registered to receive notification of that event or event type.
Event strings have the following syntax:
The parameters are optional and can be either a hexadecimal value (h) or a string (s). The maximum size of an event string is MAX_TOOL_EVENT_SIZE (300 characters). Table 4-1 lists all event parameters.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
1: The values can be either hexadecimal values (h) or strings (s). |
|||||||||||||||||||
When it registers for an event, a tool gives the target server a regular expression that matches the event string of the event the tool wants to receive. Tools can also send event strings; this allows tools attached to the same target to coordinate their activities and to exchange information or Tcl programs.
A tool can also choose not to receive any events or a subset of events. This is done by sending WTX_UNREGISTER_FOR_EVENTS. The parameter given to this command is a regular expression. Events matching this regular expression are not sent to the tool.
TEXT_ACCESS 0x3 0x4030090 0x4002344 0x4008008 0x4008608
DATA_ACCESS 0x4030090 0x3 0x4002344 0x4008008 0x4008608 0x4040000
SYM_ADD newSymbol 0x4002344 text
EXCEPTION 0x3 0x4002344 0x10 0x212900
The default method of handling events is for tools to poll the target server. Alternatively, your tool can register an event handler with the target server. In this case the target server calls the event handler when it receives an event. The following example shows the pieces of the event handler which are required to use the asynchronous event notification feature:
#include "wtx.h"
...
/* handle events */
LOCAL void eventHandler
(
WTX_EVENT_DESC * event
)
{
/* print the received event */
if (event->event != NULL)
printf ("Receeived the event : %s\n", event->event);
}
...
/* register to receive events */
if (wtxAsyncNotifyEnable (wtxh, (FUNCPTR) eventHandler) != WTX_OK)
{
/* handle error here */
...
}
...
A unique facility of WTX is its support for a compact interpreted language called Gopher. Any tool can use small Gopher scripts to request that target data structures of arbitrary complexity be retrieved from the target. The Gopher interpreter resides in the target agent. The target does not need to store dedicated routines to perform each unique request. This greatly reduces the amount of target memory required while giving users a powerful tool to access target data. Because of its power and efficiency, Gopher forms the basis of all Tornado show routines for system objects.
The Gopher execution environment is an abstract machine consisting of two objects, the pointer and the tape. The pointer is an address in the target's address space, and the tape is a one-way write-only area where Gopher results are accumulated. When the Gopher script terminates, the contents of the tape are returned to the host tool.
Table 4-2 shows the elements of the Gopher language and how they affect the pointer and the tape.
This section describes a Gopher script that traverses and collects information from the following two sample data structures:
typedef struct _node
{
UINT32 number; /* number of node */
struct _node * pNext; /* single linked list */
struct _other * pOther; /* pointer to an OTHER */
char * name; /* name of node */
UINT32 value; /* value of node */
} NODE;
typedef struct _other
{
UINT32 x1; /* X Factor One */
UINT32 x2; /* X Factor Two */
} OTHER;
Suppose you want a list of the numbers and names of each node in a list anchored at nodeList, whose elements are defined by struct _node. Initialize the Gopher pointer to the value of nodeList, nodeAddr, and dereference the pointer. Then, while the pointer is not NULL, reach into the NODE structure and write the number and name elements to the tape.
Referring to the table of Gopher elements, create the following script:
nodeAddr * { @ < +8 *$ > * }
First, initialize the pointer to the value of the symbol nodeList and then dereference it (*). You now have a pointer to the first element. While the pointer is not NULL ({), write the number field to the tape and advance the pointer (@). Saving the pointer position, enter the subroutine (<). Add eight to the value of the pointer (+8), skipping over the pNext and pOther fields. Now the pointer points to the name field. Dereference the pointer at the first character of the name string (*) and write the string to the tape ($). Exit the subroutine (>), which restores the previous value of the pointer (pointing to pNext). Dereference the pointer (*) at the next element in the list, or at NULL. If the field is not NULL, the subprogram {...} repeats. At the end, the Gopher tape contains two entries for each node in the list, one numeric value and one string value.
There are many ways to write a Gopher script. Each of the following is equivalent to the one described above:
nodeAddr * { @ +8 <*$> -8 * }Suppose you also want to find the values of x1 and x2 for a particular node. If the pointer points to the pOther member of a node and pOther is not NULL, this Gopher fragment writes the values of x1 and x2 to the tape:
* {@@ 0}
The first * replaces the pointer with the value of pOther; the fragment in braces executes only if the pointer is not NULL. The @@ fragment writes x1 and x2 to the tape, and the final 0 sets the pointer to NULL so that the {...} loop exits. Guarding this fragment in angle brackets (so that it executes with a local copy of the pointer), adding +4 to move the pointer to pOther, and inserting this fragment into the example string, you have:
nodeAddr * { @ < +8 *$ > < +4 * {@@ 0} > * }
|
|
NOTE: Wind River Systems has developed a "Gopher generator" tool which generates gopher scripts from a C structure. This tool is not supported, but is available free of charge. It can be downloaded from the Wind River System WEB server (www.wrs.com).
|
||||||||||||||||||
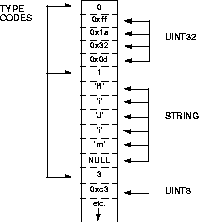
The Gopher result tape is a byte-packed data stream. The data is a series of pairs, each consisting of a type code and its associated data. The type codes are defined in the file installDir/share/src/agents/wdb/wdb.h as follows:
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The tape is formatted as shown in Figure 4-5.
The Gopher interpreter on the target agent interprets and executes the Gopher script. Any tool or application can send a Gopher script to the target agent by using the appropriate WTX command. Both Tcl and C language APIs provide commands for this purpose.
Our Gopher script assumes that nodeAddr is a pointer to the first node. To establish this pointer using Tcl, query the symbol table for the value of nodeList, and then send the Gopher script to the target agent using the Tcl procedure wtxGopherEval:
set nodeList [lindex [wtxSymFind -name nodeList] 1]
wtxGopherEval $nodeList * { @ < +8 *$ > < +4 * {@@ 0} > * }
Tcl interprets the Gopher result tape and returns a Tcl list consisting of just the data values. For our example, the Tcl API returns the following list:
{ name1 value1 x11 x21 name2 value2 ... x1n x2n )
The procedure for sending the Gopher script using C involves a similar process. First use the C routine wtxSymFind( ) to query the symbol table for the value of nodeList. Convert the value to a string, and then send this string, concatenated with the Gopher script, to the target agent using wtxGopherEval( ). C returns the byte-packed data stream without formatting it. Example 4-1 shows how to submit the Gopher script and format the result tape. For further information, see the online reference material under Tornado API Guide>WTX Tcl Library.
/* find the starting address */
if ((pSymbol = wtxSymFind (hWtx, "nodeList", NULL, 0, 0, 0)) == NULL)
{
printf ("Could not find symbol\n");
return;
}
/* convert this value to a string */
sprintf (startAddress, "0x%p", pSymbol->value);
/* free the symbol room */
wtxResultFree (hWtx, pSymbol);
/* integrate this string into the Gopher script and execute it*/
sprintf (gopherCmd, "%s * { @ < +8 *$ > < +4 * {@@ 0} > * }",
startAddress);
if ((pResult = wtxGopherEval (hWtx, gopherCmd)) == NULL)
{
printf ("gopher error: %s\n", wtxErrToMsg (hWtx,
wtxErrGet(hWtx)));
return;
}
/* format the result tape */
STATUS formatResult
(
WTX_GOPHER_TAPE pTapeResult,
char * pFinalResult
)
{
int targetByteOrder = wtxTargetEndianGet (hWtx);
int needSwap = targetByteOrder != HOST_BYTE_ORDER;
int bufIx;
bufIx = 0;
while (bufIx < pTapeResult->len)
{
char valbuf [20];
UINT8 type = pTapeResult->data [bufIx++];
unsigned char *bufp = pTapeResult->data + bufIx;
switch (type)
{
case GOPHER_UINT32:
{
UINT32 rawVal = UNPACK_32 (bufp);
sprintf (valbuf, "%#x", SWAB_32_IF (needSwap, rawVal));
strcat (pFinalResult, valbuf);
bufIx += sizeof (UINT32);
break;
}
case GOPHER_UINT16:
{
UINT16 rawVal = UNPACK_16 (bufp);
sprintf (valbuf, "%#x", SWAB_16_IF (needSwap, rawVal));
strcat (pFinalResult, valbuf);
bufIx += sizeof (UINT16);
break;
}
case GOPHER_UINT8:
{
UINT8 rawVal = *bufp;
sprintf (valbuf, "%#x", rawVal);
strcat (pFinalResult, valbuf);
bufIx += sizeof (UINT8);
break;
}
case GOPHER_FLOAT32:
{
union
{
UINT32 i;
float f;
} u;
UINT32 rawVal = UNPACK_32 (bufp);
u.i = SWAB_32_IF (needSwap, rawVal);
sprintf (valbuf, "%.8g", u.f);
strcat (pFinalResult, valbuf);
bufIx += sizeof (float);
break;
}
case GOPHER_FLOAT80:
/*
* This one is trouble. We aren't able to represent
* 80-bit floats on the host, so we just take the
* upper 64 bits and convert to double.
*/
if (targetByteOrder == LITTLE_ENDIAN)
{
/* skip over least significant 16 bits. */
bufIx += 2;
bufp += 2;
}
/* FALL THROUGH */
case GOPHER_FLOAT64:
{
union
{
UINT32 i [2];
double d;
} u;
if (needSwap)
{
u.i [1] = SWAB_32 (UNPACK_32 (bufp));
u.i [0] = SWAB_32 (UNPACK_32 (bufp+4));
}
else
{
u.i [0] = UNPACK_32 (bufp);
u.i [1] = UNPACK_32 (bufp+4);
}
sprintf (valbuf, "%.16g", u.d);
strcat (pFinalResult, valbuf);
bufIx += sizeof (double);
/*
* If target is big endian and we fell through the 80-bit
* case, we need to advance over the least-significant
* 16 bits which we have no way of converting.
*/
if (type == GOPHER_FLOAT80 && targetByteOrder == BIG_ENDIAN)
bufIx += 2;
break;
}
case GOPHER_STRING:
{
strcat (pFinalResult, pTapeResult->data + bufIx);
bufIx += strlen (pTapeResult->data + bufIx) + 1;
}
}
}
return OK;
}
![]()
![]()
![]()
![]()
![]()