![]()
![]()
![]()
![]()
![]()
VxMP provides a transparent interface that makes it easy to execute code using shared-memory objects on both a multiprocessor system and a single-processor system. After an object is created, tasks can operate on shared objects with the same routines used to operate on their corresponding local objects. For example, shared semaphores, shared message queues, and shared-memory partitions have the same syntax and interface as their local counterparts. Routines such as semGive( ), semTake( ), msgQSend( ), msgQReceive( ), memPartAlloc( ), and memPartFree( ) operate on both local and shared objects. Only the create routines are different. This allows an application to run in either a single-processor or a multiprocessor environment with only minor changes to system configuration, initialization, and object creation.
All shared-memory objects can be used on a single-processor system. This is useful for testing an application before porting it to a multiprocessor configuration. However, for objects that are used only locally, local objects always provide the best performance.
After the shared-memory facilities are initialized (see 6.4 Configuration for initialization differences), all processors are treated alike. Tasks on any CPU can create and use shared-memory objects. No processor has priority over another from a shared-memory object's point of view.1
Systems making use of shared memory can include a combination of supported architectures. This enables applications to take advantage of different processor types and still have them communicate. However, on systems where the processors have different byte ordering, you must call the macros ntohl and htonl to byte-swap the application's shared data (see VxWorks Network Programmer's Guide: TCP/IP Under VxWorks).
When an object is created, an object ID is returned to identify it. For tasks on different CPUs to access shared-memory objects, they must be able to obtain this ID. An object's ID is the same regardless of the CPU. This allows IDs to be passed using shared message queues, data structures in shared memory, or the name database.
Throughout the remainder of this chapter, system objects under discussion refer to shared objects unless otherwise indicated.
The name database allows the association of any value to any name, such as a shared-memory object's ID with a unique name. It can communicate or advertise a shared-memory block's address and object type. The name database provides name-to-value and value-to-name translation, allowing objects in the database to be accessed either by name or by value. While other methods exist for advertising an object's ID, the name database is a convenient method for doing this.
Typically the task that creates an object also advertises the object's ID by means of the name database. By adding the new object to the database, the task associates the object's ID with a name. Tasks on other processors can look up the name in the database to get the object's ID. After the task has the ID, it can use it to access the object.
For example, task t1 on CPU 1 creates an object. The object ID is returned by the creation routine and entered in the name database with the name myObj. For task t2 on CPU 0 to operate on this object, it first finds the ID by looking up the name myObj in the name database.
This same technique can be used to advertise a shared-memory address. For example, task t1 on CPU 0 allocates a chunk of memory and adds the address to the database with the name mySharedMem. Task t2 on CPU 1 can find the address of this shared memory by looking up the address in the name database using mySharedMem.
Tasks on different processors can use an agreed-upon name to get a newly created object's value. See Table 6-1 for a list of name service routines. Note that retrieving an ID from the name database need occur only one time for each task, and usually occurs during application initialization.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The name database service routines automatically convert to or from network-byte order; do not call htonl( )or ntohl( ) explicitly for values from the name database.
The object types listed in Table 6-2 are defined in smNameLib.h.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The following example shows the name database as displayed by smNameShow( ), which is automatically included if INCLUDE_SM_OBJ is selected for inclusion in the project facility VxWorks view. The parameter to smNameShow( ) specifies the level of information displayed; in this case, 1 indicates that all information is shown. For additional information on smNameShow( ), see its reference entry.
-> smNameShow 1 value = 0 = 0x0
The output is sent to the standard output device, and looks like the following:
Name in Database Max : 100 Current : 5 Free : 95 Name Value Type ----------------- ------------- ------------- myMemory 0x3835a0 SM_BLOCK myMemPart 0x3659f9 SM_PART_ID myBuff 0x383564 SM_BLOCK mySmSemaphore 0x36431d SM_SEM_B myMsgQ 0x365899 SM_MSG_Q
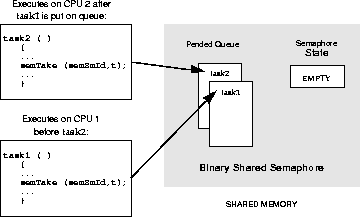
Like local semaphores, shared semaphores provide synchronization by means of atomic updates of semaphore state information. See 2. Basic OS in this manual and the reference entry for semLib for a complete discussion of semaphores. Shared semaphores can be given and taken by tasks executing on any CPU with access to the shared memory. They can be used for either synchronization of tasks running on different CPUs or mutual exclusion for shared resources.
To use a shared semaphore, a task creates the semaphore and advertises its ID. This can be done by adding it to the name database. A task on any CPU in the system can use the semaphore by first getting the semaphore ID (for example, from the name database). When it has the ID, it can then take or give the semaphore.
In the case of employing shared semaphores for mutual exclusion, typically there is a system resource that is shared between tasks on different CPUs and the semaphore is used to prevent concurrent access. Any time a task requires exclusive access to the resource, it takes the semaphore. When the task is finished with the resource, it gives the semaphore.
For example, there are two tasks, t1 on CPU 0 and t2 on CPU 1. Task t1 creates the semaphore and advertises the semaphore's ID by adding it to the database and assigning the name myMutexSem. Task t2 looks up the name myMutexSem in the database to get the semaphore's ID. Whenever a task wants to access the resource, it first takes the semaphore by using the semaphore ID. When a task is done using the resource, it gives the semaphore.
In the case of employing shared semaphores for synchronization, assume a task on one CPU must notify a task on another CPU that some event has occurred. The task being synchronized pends on the semaphore waiting for the event to occur. When the event occurs, the task doing the synchronizing gives the semaphore.
For example, there are two tasks, t1 on CPU 0 and t2 on CPU 1. Both t1 and t2 are monitoring robotic arms. The robotic arm that is controlled by t1 is passing a physical object to the robotic arm controlled by t2. Task t2 moves the arm into position but must then wait until t1 indicates that it is ready for t2 to take the object. Task t1 creates the shared semaphore and advertises the semaphore's ID by adding it to the database and assigning the name objReadySem. Task t2 looks up the name objReadySem in the database to get the semaphore's ID. It then takes the semaphore by using the semaphore ID. If the semaphore is unavailable, t2 pends, waiting for t1 to indicate that the object is ready for t2. When t1 is ready to transfer control of the object to t2, it gives the semaphore, readying t2 on CPU1.
There are two types of shared semaphores, binary and counting. Shared semaphores have their own create routines and return a SEM_ID. Table 6-3 lists the create routines. All other semaphore routines, except semDelete( ), operate transparently on the created shared semaphore.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The use of shared semaphores and local semaphores differs in several ways:
Use semInfo( ) to get the shared task control block of tasks pended on a shared semaphore. Use semShow( ), if INCLUDE_SEM_SHOW is included in the project facility VxWorks view, to display the status of the shared semaphore and a list of pended tasks. The following example displays detailed information on the shared semaphore mySmSemaphoreId as indicated by the second argument (0 = summary, 1 = details):
-> semShow mySmSemaphoreId, 1 value = 0 = 0x0
The output is sent to the standard output device, and looks like the following:
Semaphore Id : 0x36431d Semaphore Type : SHARED BINARY Task Queuing : FIFO Pended Tasks : 2 State : EMPTY TID CPU Number Shared TCB ------------- ------------- -------------- 0xd0618 1 0x364204 0x3be924 0 0x36421c
The following code example depicts two tasks executing on different CPUs and using shared semaphores. The routine semTask1( ) creates the shared semaphore, initializing the state to full. It adds the semaphore to the name database (to enable the task on the other CPU to access it), takes the semaphore, does some processing, and gives the semaphore. The routine semTask2( ) gets the semaphore ID from the database, takes the semaphore, does some processing, and gives the semaphore.
/* semExample.h - shared semaphore example header file */ #define SEM_NAME "mySmSemaphore" /* semTask1.c - shared semaphore example */ /* This code is executed by a task on CPU #1 */ #include "vxWorks.h" #include "semLib.h" #include "semSmLib.h" #include "smNameLib.h" #include "stdio.h" #include "taskLib.h" #include "semExample.h"
/* semTask2.c - shared semaphore example */
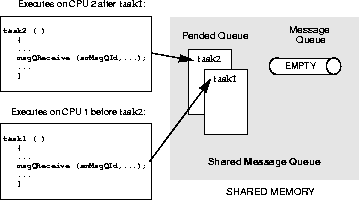
Shared message queues are FIFO queues used by tasks to send and receive variable-length messages on any of the CPUs that have access to the shared memory. They can be used either to synchronize tasks or to exchange data between tasks running on different CPUs. See 2. Basic OS in this manual and the reference entry for msgQLib for a complete discussion of message queues.
To use a shared message queue, a task creates the message queue and advertises its ID. A task that wants to send or receive a message with this message queue first gets the message queue's ID. It then uses this ID to access the message queue.
For example, consider a typical server/client scenario where a server task t1 (on CPU 1) reads requests from one message queue and replies to these requests with a different message queue. Task t1 creates the request queue and advertises its ID by adding it to the name database assigning the name requestQue. If task t2 (on CPU 0) wants to send a request to t1, it first gets the message queue ID by looking up the name requestQue in the name database. Before sending its first request, task t2 creates a reply message queue. Instead of adding its ID to the database, it advertises the ID by sending it as part of the request message. When t1 receives the request from the client, it finds in the message the ID of the queue to use when replying to that client. Task t1 then sends the reply to the client by using this ID.
To pass messages between tasks on different CPUs, first create the message queue by calling msgQSmCreate( ). This routine returns a MSG_Q_ID. This ID is used for sending and receiving messages on the shared message queue.
Like their local counterparts, shared message queues can send both urgent or normal priority messages.
The use of shared message queues and local message queues differs in several ways:
To achieve optimum performance with shared message queues, align send and receive buffers on 4-byte boundaries.
To display the status of the shared message queue as well as a list of tasks pended on the queue, select INCLUDE_MSG_Q_SHOW for inclusion in the project facility VxWorks view and call msgQShow( ). The following example displays detailed information on the shared message queue 0x7f8c21 as indicated by the second argument (0 = summary display, 1 = detailed display).
-> msgQShow 0x7f8c21, 1 value = 0 = 0x0
The output is sent to the standard output device, and looks like the following:
Message Queue Id : 0x7f8c21 Task Queuing : FIFO Message Byte Len : 128 Messages Max : 10 Messages Queued : 0 Receivers Blocked : 1 Send timeouts : 0 Receive timeouts : 0 Receivers blocked : TID CPU Number Shared TCB ---------- -------------------- -------------- 0xd0618 1 0x1364204
In the following code example, two tasks executing on different CPUs use shared message queues to pass data to each other. The server task creates the request message queue, adds it to the name database, and reads a message from the queue. The client task gets the smRequestQId from the name database, creates a reply message queue, bundles the ID of the reply queue as part of the message, and sends the message to the server. The server gets the ID of the reply queue and uses it to send a message back to the client. This technique requires the use of the network byte-order conversion macros htonl( ) and ntohl( ), because the numeric queue ID is passed over the network in a data field.
/* msgExample.h - shared message queue example header file */
/* server.c - shared message queue example server */
/* client.c - shared message queue example client */
The shared-memory allocator allows tasks on different CPUs to allocate and release variable size chunks of memory that are accessible from all CPUs with access to the shared-memory system. Two sets of routines are provided: low-level routines for manipulating user-created shared-memory partitions, and high-level routines for manipulating a shared-memory partition dedicated to the shared-memory system pool. (This organization is similar to that used by the local-memory manager, memPartLib.)
Shared-memory blocks can be allocated from different partitions. Both a shared-memory system partition and user-created partitions are available. User-created partitions can be created and used for allocating data blocks of a particular size. Memory fragmentation is avoided when fixed-sized blocks are allocated from user-created partitions dedicated to a particular block size.
To use the shared-memory system partition, a task allocates a shared-memory block and advertises its address. One way of advertising the ID is to add the address to the name database. The routine used to allocate a block from the shared-memory system partition returns a local address. Before the address is advertised to tasks on other CPUs, this local address must be converted to a global address. Any task that must use the shared memory must first get the address of the memory block and convert the global address to a local address. When the task has the address, it can use the memory.
However, to address issues of mutual exclusion, typically a shared semaphore is used to protect the data in the shared memory. Thus in a more common scenario, the task that creates the shared memory (and adds it to the database) also creates a shared semaphore. The shared semaphore ID is typically advertised by storing it in a field in the shared data structure residing in the shared-memory block. The first time a task must access the shared data structure, it looks up the address of the memory in the database and gets the semaphore ID from a field in the shared data structure. Whenever a task must access the shared data, it must first take the semaphore. Whenever a task is finished with the shared data, it must give the semaphore.
For example, assume two tasks executing on two different CPUs must share data. Task t1 executing on CPU 1 allocates a memory block from the shared-memory system partition and converts the local address to a global address. It then adds the global address of the shared data to the name database with the name mySharedData. Task t1 also creates a shared semaphore and stores the ID in the first field of the data structure residing in the shared memory. Task t2 executing on CPU 2 looks up the name mySharedData in the name database to get the address of the shared memory. It then converts this address to a local address. Before accessing the data in the shared memory, t2 gets the shared semaphore ID from the first field of the data structure residing in the shared-memory block. It then takes the semaphore before using the data and gives the semaphore when it is done using the data.
To make use of user-created shared-memory partitions, a task creates a shared-memory partition and adds it to the name database. Before a task can use the shared-memory partition, it must first look in the name database to get the partition ID. When the task has the partition ID, it can access the memory in the shared-memory partition.
For example, task t1 creates a shared-memory partition and adds it to the name database using the name myMemPartition. Task t2 executing on another CPU wants to allocate memory from the new partition. Task t2 first looks up myMemPartition in the name database to get the partition ID. It can then allocate memory from it, using the ID.
The shared-memory system partition is analogous to the system partition for local memory. Table 6-4 lists routines for manipulating the shared-memory system partition.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
Routines that return a pointer to allocated memory return a local address (that is, an address suitable for use from the local CPU). To share this memory across processors, this address must be converted to a global address before it is advertised to tasks on other CPUs. Before a task on another CPU uses the memory, it must convert the global address to a local address. Macros and routines are provided to convert between local addresses and global addresses; see the header file smObjLib.h and the reference entry for smObjLib.
The following code example uses memory from the shared-memory system partition to share data between tasks on different CPUs. The first member of the data structure is a shared semaphore that is used for mutual exclusion. The send task creates and initializes the structure, then the receive task accesses the data and displays it.
/* buffProtocol.h - simple buffer exchange protocol header file */
/* buffSend.c - simple buffer exchange protocol send side */
/* buffReceive.c - simple buffer exchange protocol receive side */
Shared-memory partitions have a separate create routine, memPartSmCreate( ), that returns a MEM_PART_ID. After a user-defined shared-memory partition is created, routines in memPartLib operate on it transparently. Note that the address of the shared-memory area passed to memPartSmCreate( ) (or memPartAddToPool( )) must be the global address.
This example is similar to Example 6-3, which uses the shared-memory system partition. This example creates a user-defined partition and stores the shared data in this new partition. A shared semaphore is used to protect the data.
/* memPartExample.h - shared memory partition example header file */
/* memPartSend.c - shared memory partition example send side */
/* memPartReceive.c - shared memory partition example receive side */
Like their local counterparts, shared-memory partitions (both system- and user-created) can have different options set for error handling; see the reference entries for memPartOptionsSet( ) and smMemOptionsSet( ).
If the MEM_BLOCK_CHECK option is used in the following situation, the system can get into a state where the memory partition is no longer available. If a task attempts to free a bad block and a bus error occurs, the task is suspended. Because shared semaphores are used internally for mutual exclusion, the suspended task still has the semaphore, and no other task has access to the memory partition. By default, shared-memory partitions are created without the MEM_BLOCK_CHECK option.
1: Do not confuse this type of priority with the CPU priorities associated with VMEbus access.
![]()
![]()
![]()
![]()
![]()