![]()
![]()
![]()
![]()
![]()
The complement to the multitasking routines described in the 2.3 Tasks is the intertask communication facilities. These facilities permit independent tasks to coordinate their actions.
VxWorks supplies a rich set of intertask communication mechanisms, including:
The most obvious way for tasks to communicate is by accessing shared data structures. Because all tasks in VxWorks exist in a single linear address space, sharing data structures between tasks is trivial; see Figure 2-8. Global variables, linear buffers, ring buffers, linked lists, and pointers can be referenced directly by code running in different contexts.
While a shared address space simplifies exchange of data, interlocking access to memory is crucial to avoid contention. Many methods exist for obtaining exclusive access to resources, and vary only in the scope of the exclusion. Such methods include disabling interrupts, disabling preemption, and resource locking with semaphores.
The most powerful method available for mutual exclusion is the disabling of interrupts. Such a lock guarantees exclusive access to the CPU:
funcA ()
{
int lock = intLock();
.
. critical region that cannot be interrupted
.
intUnlock (lock);
}
While this solves problems involving mutual exclusion with ISRs, it is inappropriate as a general-purpose mutual-exclusion method for most real-time systems, because it prevents the system from responding to external events for the duration of these locks. Interrupt latency is unacceptable whenever an immediate response to an external event is required. However, interrupt locking can sometimes be necessary where mutual exclusion involves ISRs. In any situation, keep the duration of interrupt lockouts short.
Disabling preemption offers a somewhat less restrictive form of mutual exclusion. While no other task is allowed to preempt the current executing task, ISRs are able to execute:
funcA ()
{
taskLock ();
.
. critical region that cannot be interrupted
.
taskUnlock ();
}
However, this method can lead to unacceptable real-time response. Tasks of higher priority are unable to execute until the locking task leaves the critical region, even though the higher-priority task is not itself involved with the critical region. While this kind of mutual exclusion is simple, if you use it, make sure to keep the duration short. A better mechanism is provided by semaphores, discussed in 2.4.3 Semaphores.
VxWorks semaphores are highly optimized and provide the fastest intertask communication mechanism in VxWorks. Semaphores are the primary means for addressing the requirements of both mutual exclusion and task synchronization:
VxWorks provides not only the Wind semaphores, designed expressly for VxWorks, but also POSIX semaphores, designed for portability. An alternate semaphore library provides the POSIX-compatible semaphore interface; see POSIX Semaphores.
The semaphores described here are for use on a single CPU. The optional product VxMP provides semaphores that can be used across processors; see 6. Shared-Memory Objects.
Instead of defining a full set of semaphore control routines for each type of semaphore, the Wind semaphores provide a single uniform interface for semaphore control. Only the creation routines are specific to the semaphore type. Table 2-13 lists the semaphore control routines.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The semBCreate( ), semMCreate( ), and semCCreate( ) routines return a semaphore ID that serves as a handle on the semaphore during subsequent use by the other semaphore-control routines. When a semaphore is created, the queue type is specified. Tasks pending on a semaphore can be queued in priority order (SEM_Q_PRIORITY) or in first-in first-out order (SEM_Q_FIFO).
|
|
WARNING: The semDelete( ) call terminates a semaphore and deallocates any associated memory. Take care when deleting semaphores, particularly those used for mutual exclusion, to avoid deleting a semaphore that another task still requires. Do not delete a semaphore unless the same task first succeeds in taking it.
|
||||||||||||||||||
The general-purpose binary semaphore is capable of addressing the requirements of both forms of task coordination: mutual exclusion and synchronization. The binary semaphore has the least overhead associated with it, making it particularly applicable to high-performance requirements. The mutual-exclusion semaphore described in Mutual-Exclusion Semaphores is also a binary semaphore, but it has been optimized to address problems inherent to mutual exclusion. Alternatively, the binary semaphore can be used for mutual exclusion if the advanced features of the mutual-exclusion semaphore are deemed unnecessary.
A binary semaphore can be viewed as a flag that is available (full) or unavailable (empty). When a task takes a binary semaphore, with semTake( ), the outcome depends on whether the semaphore is available (full) or unavailable (empty) at the time of the call; see Figure 2-9. If the semaphore is available (full), the semaphore becomes unavailable (empty) and the task continues executing immediately. If the semaphore is unavailable (empty), the task is put on a queue of blocked tasks and enters a state of pending on the availability of the semaphore.
When a task gives a binary semaphore, using semGive( ), the outcome also depends on whether the semaphore is available (full) or unavailable (empty) at the time of the call; see Figure 2-10. If the semaphore is already available (full), giving the semaphore has no effect at all. If the semaphore is unavailable (empty) and no task is waiting to take it, then the semaphore becomes available (full). If the semaphore is unavailable (empty) and one or more tasks are pending on its availability, then the first task in the queue of blocked tasks is unblocked, and the semaphore is left unavailable (empty).
Binary semaphores interlock access to a shared resource efficiently. Unlike disabling interrupts or preemptive locks, binary semaphores limit the scope of the mutual exclusion to only the associated resource. In this technique, a semaphore is created to guard the resource. Initially the semaphore is available (full).
/* includes */
#include "vxWorks.h"
#include "semLib.h"
SEM_ID semMutex;
/* Create a binary semaphore that is initially full. Tasks *
* blocked on semaphore wait in priority order. */
semMutex = semBCreate (SEM_Q_PRIORITY, SEM_FULL);
When a task wants to access the resource, it must first take that semaphore. As long as the task keeps the semaphore, all other tasks seeking access to the resource are blocked from execution. When the task is finished with the resource, it gives back the semaphore, allowing another task to use the resource.
Thus all accesses to a resource requiring mutual exclusion are bracketed with semTake( ) and semGive( ) pairs:
semTake (semMutex, WAIT_FOREVER);
.
. critical region, only accessible by a single task at a time
.
semGive (semMutex);
When used for task synchronization, a semaphore can represent a condition or event that a task is waiting for. Initially the semaphore is unavailable (empty). A task or ISR signals the occurrence of the event by giving the semaphore (see 2.5 Interrupt Service Code for a complete discussion of ISRs). Another task waits for the semaphore by calling semTake( ). The waiting task blocks until the event occurs and the semaphore is given.
Note the difference in sequence between semaphores used for mutual exclusion and those used for synchronization. For mutual exclusion, the semaphore is initially full, and each task first takes, then gives back the semaphore. For synchronization, the semaphore is initially empty, and one task waits to take the semaphore given by another task.
In Example 2-4, the init( ) routine creates the binary semaphore, attaches an ISR to an event, and spawns a task to process the event. The routine task1( ) runs until it calls semTake( ). It remains blocked at that point until an event causes the ISR to call semGive( ). When the ISR completes, task1( ) executes to process the event. There is an advantage of handling event processing within the context of a dedicated task: less processing takes place at interrupt level, thereby reducing interrupt latency. This model of event processing is recommended for real-time applications.
/* This example shows the use of semaphores for task synchronization. */
/* includes */
#include "vxWorks.h"
#include "semLib.h"
#include "arch/arch/ivarch.h" /* replace arch with architecture type */
SEM_ID syncSem; /* ID of sync semaphore */
init (
int someIntNum
)
{
/* connect interrupt service routine */
intConnect (INUM_TO_IVEC (someIntNum), eventInterruptSvcRout, 0);
/* create semaphore */
syncSem = semBCreate (SEM_Q_FIFO, SEM_EMPTY);
/* spawn task used for synchronization. */
taskSpawn ("sample", 100, 0, 20000, task1, 0,0,0,0,0,0,0,0,0,0);
}
task1 (void)
{
...
semTake (syncSem, WAIT_FOREVER); /* wait for event to occur */
printf ("task 1 got the semaphore\n");
... /* process event */
}
eventInterruptSvcRout (void)
{
...
semGive (syncSem); /* let task 1 process event */
...
}
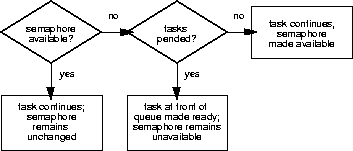
Broadcast synchronization allows all processes that are blocked on the same semaphore to be unblocked atomically. Correct application behavior often requires a set of tasks to process an event before any task of the set has the opportunity to process further events. The routine semFlush( ) addresses this class of synchronization problem by unblocking all tasks pended on a semaphore.
The mutual-exclusion semaphore is a specialized binary semaphore designed to address issues inherent in mutual exclusion, including priority inversion, deletion safety, and recursive access to resources.
The fundamental behavior of the mutual-exclusion semaphore is identical to the binary semaphore, with the following exceptions:
Priority inversion arises when a higher-priority task is forced to wait an indefinite period of time for a lower-priority task to complete. Consider the scenario in Figure 2-11: t1, t2, and t3 are tasks of high, medium, and low priority, respectively. t3 has acquired some resource by taking its associated binary guard semaphore. When t1 preempts t3 and contends for the resource by taking the same semaphore, it becomes blocked. If we could be assured that t1 would be blocked no longer than the time it normally takes t3 to finish with the resource, there would be no problem because the resource cannot be preempted. However, the low-priority task is vulnerable to preemption by medium-priority tasks (like t2), which could inhibit t3 from relinquishing the resource. This condition could persist, blocking t1 for an indefinite period of time.
The mutual-exclusion semaphore has the option SEM_INVERSION_SAFE, which enables a priority-inheritance algorithm. The priority-inheritance protocol assures that a task that owns a resource executes at the priority of the highest-priority task blocked on that resource. Once the task priority has been elevated, it remains at the higher level until all mutual-exclusion semaphores that the task owns are released; then the task returns to its normal, or standard, priority. Hence, the "inheriting" task is protected from preemption by any intermediate-priority tasks. This option must be used in conjunction with a priority queue (SEM_Q_PRIORITY).
In Figure 2-12, priority inheritance solves the problem of priority inversion by elevating the priority of t3 to the priority of t1 during the time t1 is blocked on the semaphore. This protects t3, and indirectly t1, from preemption by t2.
The following example creates a mutual-exclusion semaphore that uses the priority inheritance algorithm:
semId = semMCreate (SEM_Q_PRIORITY | SEM_INVERSION_SAFE);
Another problem of mutual exclusion involves task deletion. Within a critical region guarded by semaphores, it is often desirable to protect the executing task from unexpected deletion. Deleting a task executing in a critical region can be catastrophic. The resource might be left in a corrupted state and the semaphore guarding the resource left unavailable, effectively preventing all access to the resource.
The primitives taskSafe( ) and taskUnsafe( ) provide one solution to task deletion. However, the mutual-exclusion semaphore offers the option SEM_DELETE_SAFE, which enables an implicit taskSafe( ) with each semTake( ), and a taskUnsafe( ) with each semGive( ). In this way, a task can be protected from deletion while it has the semaphore. This option is more efficient than the primitives taskSafe( ) and taskUnsafe( ), as the resulting code requires fewer entrances to the kernel.
semId = semMCreate (SEM_Q_FIFO | SEM_DELETE_SAFE);
Mutual-exclusion semaphores can be taken recursively. This means that the semaphore can be taken more than once by the task that owns it before finally being released. Recursion is useful for a set of routines that must call each other but that also require mutually exclusive access to a resource. This is possible because the system keeps track of which task currently owns the mutual-exclusion semaphore.
Before being released, a mutual-exclusion semaphore taken recursively must be given the same number of times it is taken. This is tracked by a count that increments with each semTake( ) and decrements with each semGive( ).
/* Function A requires access to a resource which it acquires by taking * mySem; function A may also need to call function B, which also * requires mySem: */
Counting semaphores are another means to implement task synchronization and mutual exclusion. The counting semaphore works like the binary semaphore except that it keeps track of the number of times a semaphore is given. Every time a semaphore is given, the count is incremented; every time a semaphore is taken, the count is decremented. When the count reaches zero, a task that tries to take the semaphore is blocked. As with the binary semaphore, if a semaphore is given and a task is blocked, it becomes unblocked. However, unlike the binary semaphore, if a semaphore is given and no tasks are blocked, then the count is incremented. This means that a semaphore that is given twice can be taken twice without blocking. Table 2-14 shows an example time sequence of tasks taking and giving a counting semaphore that was initialized to a count of 3.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
Counting semaphores are useful for guarding multiple copies of resources. For example, the use of five tape drives might be coordinated using a counting semaphore with an initial count of 5, or a ring buffer with 256 entries might be implemented using a counting semaphore with an initial count of 256. The initial count is specified as an argument to the semCCreate( ) routine.
The uniform Wind semaphore interface includes two special options. These options are not available for the POSIX-compatible semaphores described in POSIX Semaphores.
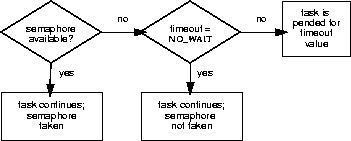
Wind semaphores include the ability to time out from the pended state. This is controlled by a parameter to semTake( ) that specifies the amount of time in ticks that the task is willing to wait in the pended state. If the task succeeds in taking the semaphore within the allotted time, semTake( ) returns OK. The errno set when a semTake( ) returns ERROR due to timing out before successfully taking the semaphore depends upon the timeout value passed. A semTake( ) with NO_WAIT (0), which means do not wait at all, sets errno to S_objLib_OBJ_UNAVAILABLE. A semTake( ) with a positive timeout value returns S_objLib_OBJ_TIMEOUT. A timeout value of WAIT_FOREVER (-1) means wait indefinitely.
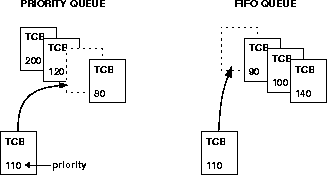
Wind semaphores include the ability to select the queuing mechanism employed for tasks blocked on a semaphore. They can be queued based on either of two criteria: first-in first-out (FIFO) order, or priority order; see Figure 2-13.
Priority ordering better preserves the intended priority structure of the system at the expense of some overhead in semTake( ) in sorting the tasks by priority. A FIFO queue requires no priority sorting overhead and leads to constant-time performance. The selection of queue type is specified during semaphore creation with semBCreate( ), semMCreate( ), or semCCreate( ). Semaphores using the priority inheritance option (SEM_INVERSION_SAFE) must select priority-order queuing.
POSIX defines both named and unnamed semaphores, which have the same properties, but use slightly different interfaces. The POSIX semaphore library provides routines for creating, opening, and destroying both named and unnamed semaphores. The POSIX semaphore routines provided by semPxLib are shown in Table 2-15.
With named semaphores, you assign a symbolic name1 when opening the semaphore; the other named-semaphore routines accept this name as an argument.
The POSIX terms wait (or lock) and post (or unlock) correspond to the VxWorks terms take and give, respectively.
The initialization routine semPxLibInit( ) is called by default when INCLUDE_POSIX_SEM is selected for inclusion in the project facility VxWorks view. The routines sem_open( ), sem_unlink( ), and sem_close( ) are for opening and closing/destroying named semaphores only; sem_init( ) and sem_destroy( ) are for initializing and destroying unnamed semaphores only. The routines for locking, unlocking, and getting the value of semaphores are used for both named and unnamed semaphores.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
WARNING: The sem_destroy( ) call terminates an unnamed semaphore and deallocates any associated memory; the combination of sem_close( ) and sem_unlink( ) has the same effect for named semaphores. Take care when deleting semaphores, particularly mutual exclusion semaphores, to avoid deleting a semaphore still required by another task. Do not delete a semaphore unless the deleting task first succeeds in locking that semaphore. (Likewise, for named semaphores, close semaphores only from the same task that opens them.)
|
||||||||||||||||||
POSIX semaphores are counting semaphores; that is, they keep track of the number of times they are given.
The Wind semaphore mechanism is similar to that specified by POSIX, except that Wind semaphores offer additional features: priority inheritance, task-deletion safety, the ability for a single task to take a semaphore multiple times, ownership of mutual-exclusion semaphores, semaphore timeouts, and the choice of queuing mechanism. When these features are important, Wind semaphores are preferable.
In using unnamed semaphores, normally one task allocates memory for the semaphore and initializes it. A semaphore is represented with the data structure sem_t, defined in semaphore.h. The semaphore initialization routine, sem_init( ), allows you to specify the initial value.
Once the semaphore is initialized, any task can use the semaphore by locking it with sem_wait( ) (blocking) or sem_trywait( ) (non-blocking), and unlocking it with sem_post( ).
As noted earlier, semaphores can be used for both synchronization and mutual exclusion. When a semaphore is used for synchronization, it is typically initialized to zero (locked). The task waiting to be synchronized blocks on a sem_wait( ). The task doing the synchronizing unlocks the semaphore using sem_post( ). If the task blocked on the semaphore is the only one waiting for that semaphore, the task unblocks and becomes ready to run. If other tasks are blocked on the semaphore, the task with the highest priority is unblocked.
When a semaphore is used for mutual exclusion, it is typically initialized to a value greater than zero (meaning that the resource is available). Therefore, the first task to lock the semaphore does so without blocking; subsequent tasks block (if the semaphore value was initialized to 1).
/* This example uses unnamed semaphores to synchronize an action between * the calling task and a task that it spawns (tSyncTask). To run from * the shell, spawn as a task: * -> sp unnameSem */
The sem_open( ) routine either opens a named semaphore that already exists, or, as an option, creates a new semaphore. You can specify which of these possibilities you want by combining the following flag values:
The possible effects of a call to sem_open( ), depending on which flags are set and on whether the semaphore accessed already exists, are shown in Table 2-16. There is no entry for O_EXCL alone, because using that flag alone is not meaningful.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
A POSIX named semaphore, once initialized, remains usable until explicitly destroyed. Tasks can explicitly mark a semaphore for destruction at any time, but the semaphore remains in the system until no task has the semaphore open.
If INCLUDE_POSIX_SEM_SHOW is selected for inclusion in the project facility VxWorks view (for details, see Tornado User's Guide: Projects), you can use show( ) from the Tornado shell to display information about a POSIX semaphore:2
The output is sent to the standard output device, and provides information about the POSIX semaphore mySem with two tasks blocked waiting for it:
For a group of collaborating tasks to use a named semaphore, one of the tasks first creates and initializes the semaphore (by calling sem_open( ) with the O_CREAT flag). Any task that needs to use the semaphore thereafter opens it by calling sem_open( ) with the same name (but without setting O_CREAT). Any task that has opened the semaphore can use it by locking it with sem_wait( ) (blocking) or sem_trywait( ) (non-blocking) and unlocking it with sem_post( ).
To remove a semaphore, all tasks using it must first close it with sem_close( ), and one of the tasks must also unlink it. Unlinking a semaphore with sem_unlink( )removes the semaphore name from the name table. After the name is removed from the name table, tasks that currently have the semaphore open can still use it, but no new tasks can open this semaphore. The next time a task tries to open the semaphore without the O_CREAT flag, the operation fails. The semaphore vanishes when the last task closes it.
/* In this example, nameSem() creates a task for synchronization. The * new task, tSyncSemTask, blocks on the semaphore created in nameSem(). * Once the synchronization takes place, both tasks close the semaphore, * and nameSem() unlinks it. To run this task from the shell, spawn * nameSem as a task: * -> sp nameSem, "myTest" */
Modern real-time applications are constructed as a set of independent but cooperating tasks. While semaphores provide a high-speed mechanism for the synchronization and interlocking of tasks, often a higher-level mechanism is necessary to allow cooperating tasks to communicate with each other. In VxWorks, the primary intertask communication mechanism within a single CPU is message queues. The optional product, VxMP, provides global message queues that can be used across processors; for more information, see 6. Shared-Memory Objects.
Message queues allow a variable number of messages, each of variable length, to be queued. Any task or ISR can send messages to a message queue. Any task can receive messages from a message queue. Multiple tasks can send to and receive from the same message queue. Full-duplex communication between two tasks generally requires two message queues, one for each direction; see Figure 2-14.
There are two message-queue subroutine libraries in VxWorks. The first of these, msgQLib, provides Wind message queues, designed expressly for VxWorks; the second, mqPxLib, is compatible with the POSIX standard (1003.1b) for real-time extensions. See Comparison of POSIX and Wind Message Queues for a discussion of the differences between the two message-queue designs.
Wind message queues are created and deleted with the routines shown in Table 2-17. This library provides messages that are queued in FIFO order, with a single exception: there are two priority levels, and messages marked as high priority are attached to the head of the queue.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
A message queue is created with msgQCreate( ). Its parameters specify the maximum number of messages that can be queued in the message queue and the maximum length in bytes of each message. Enough buffer space is preallocated for the specified number and length of messages.
A task or ISR sends a message to a message queue with msgQSend( ). If no tasks are waiting for messages on that queue, the message is added to the queue's buffer of messages. If any tasks are already waiting for a message from that message queue, the message is immediately delivered to the first waiting task.
A task receives a message from a message queue with msgQReceive( ). If messages are already available in the message queue's buffer, the first message is immediately dequeued and returned to the caller. If no messages are available, then the calling task blocks and is added to a queue of tasks waiting for messages. This queue of waiting tasks can be ordered either by task priority or FIFO, as specified in an option parameter when the queue is created.
Both msgQSend( ) and msgQReceive( ) take timeout parameters. When sending a message, the timeout specifies how many ticks to wait for buffer space to become available, if no space is available to queue the message. When receiving a message, the timeout specifies how many ticks to wait for a message to become available, if no message is immediately available. As with semaphores, the value of the timeout parameter can have the special values of NO_WAIT (0), meaning always return immediately, or WAIT_FOREVER (-1), meaning never time out the routine.
/* In this example, task t1 creates the message queue and sends a message * to task t2. Task t2 receives the message from the queue and simply * displays the message. */
The POSIX message queue routines, provided by mqPxLib, are shown in Table 2-18. These routines are similar to Wind message queues, except that POSIX message queues provide named queues and messages with a range of priorities.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The initialization routine mqPxLibInit( ) makes the POSIX message queue routines available; the system initialization code must call it before any tasks use POSIX message queues. As shipped, usrInit( ) calls mqPxLibInit( ) when INCLUDE_POSIX_MQ is selected for inclusion in the project facility VxWorks view.
Before a set of tasks can communicate through a POSIX message queue, one of the tasks must create the message queue by calling mq_open( ) with the O_CREAT flag set. Once a message queue is created, other tasks can open that queue by name to send and receive messages on it. Only the first task opens the queue with the O_CREAT flag; subsequent tasks can open the queue for receiving only (O_RDONLY), sending only (O_WRONLY), or both sending and receiving (O_RDWR).
To put messages on a queue, use mq_send( ). If a task attempts to put a message on the queue when the queue is full, the task blocks until some other task reads a message from the queue, making space available. To avoid blocking on mq_send( ), set O_NONBLOCK when you open the message queue. In that case, when the queue is full, mq_send( ) returns -1 and sets errno to EAGAIN instead of pending, allowing you to try again or take other action as appropriate.
One of the arguments to mq_send( ) specifies a message priority. Priorities range from 0 (lowest priority) to 31 (highest priority).
When a task receives a message using mq_receive( ), the task receives the highest-priority message currently on the queue. Among multiple messages with the same priority, the first message placed on the queue is the first received (FIFO order). If the queue is empty, the task blocks until a message is placed on the queue. To avoid pending on mq_receive( ), open the message queue with O_NONBLOCK; in that case, when a task attempts to read from an empty queue, mq_receive( ) returns -1 and sets errno to EAGAIN.
To close a message queue, call mq_close( ). Closing the queue does not destroy it, but only asserts that your task is no longer using the queue. To request that the queue be destroyed, call mq_unlink( ). Unlinking a message queue does not destroy the queue immediately, but it does prevent any further tasks from opening that queue, by removing the queue name from the name table. Tasks that currently have the queue open can continue to use it. When the last task closes an unlinked queue, the queue is destroyed.
/* In this example, the mqExInit() routine spawns two tasks that * communicate using the message queue. */
A task can use the mq_notify( ) routine to request notification when a message for it arrives at an empty queue. The advantage of this is that a task can avoid blocking or polling to wait for a message.
The mq_notify( )call specifies a signal to be sent to the task when a message is placed on an empty queue. This mechanism uses the POSIX data-carrying extension to signaling, which allows you, for example, to carry a queue identifier with the signal (see POSIX Queued Signals).
The mq_notify( )mechanism is designed to alert the task only for new messages that are actually available. If the message queue already contains messages, no notification is sent when more messages arrive. If there is another task that is blocked on the queue with mq_receive( ), that other task unblocks, and no notification is sent to the task registered with mq_notify( ).
Notification is exclusive to a single task: each queue can register only one task for notification at a time. Once a queue has a task to notify, no attempts to register with mq_notify( )can succeed until the notification request is satisfied or cancelled.
Once a queue sends notification to a task, the notification request is satisfied, and the queue has no further special relationship with that particular task; that is, the queue sends a notification signal only once per mq_notify( )request. To arrange for one particular task to continue receiving notification signals, the best approach is to call mq_notify( )from the same signal handler that receives the notification signals. This reinstalls the notification request as soon as possible.
To cancel a notification request, specify NULL instead of a notification signal. Only the currently registered task can cancel its notification request.
/* In this example, a task uses mq_notify() to discover when a message * is waiting for it on a previously empty queue. */
/* This example sets the O_NONBLOCK flag, and examines message queue * attributes. */
The two forms of message queues solve many of the same problems, but there are some significant differences. Table 2-19 summarizes the main differences between the two forms of message queues.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
Another feature of POSIX message queues is, of course, portability: if you are migrating to VxWorks from another 1003.1b-compliant system, using POSIX message queues enables you to leave that part of the code unchanged, reducing the porting effort.
The VxWorks show( ) command produces a display of the key message queue attributes, for either kind of message queue3 . For example, if mqPXId is a POSIX message queue:
The output is sent to the standard output device, and looks like the following:
Message queue name : MyQueue No. of messages in queue : 1 Maximum no. of messages : 16 Maximum message size : 16
Compare this to the output when myMsgQId is a Wind message queue:4
Real-time systems are often structured using a client-server model of tasks. In this model, server tasks accept requests from client tasks to perform some service, and usually return a reply. The requests and replies are usually made in the form of intertask messages. In VxWorks, message queues or pipes (see 2.4.5 Pipes) are a natural way to implement this.
For example, client-server communications might be implemented as shown in Figure 2-15. Each server task creates a message queue to receive request messages from clients. Each client task creates a message queue to receive reply messages from servers. Each request message includes a field containing the msgQId of the client's reply message queue. A server task's "main loop" consists of reading request messages from its request message queue, performing the request, and sending a reply to the client's reply message queue.
The same architecture can be achieved with pipes instead of message queues, or by other means that are tailored to the needs of the particular application.
Pipes provide an alternative interface to the message queue facility that goes through the VxWorks I/O system. Pipes are virtual I/O devices managed by the driver pipeDrv. The routine pipeDevCreate( ) creates a pipe device and the underlying message queue associated with that pipe. The call specifies the name of the created pipe, the maximum number of messages that can be queued to it, and the maximum length of each message:
The created pipe is a normally named I/O device. Tasks can use the standard I/O routines to open, read, and write pipes, and invoke ioctl routines. As they do with other I/O devices, tasks block when they read from an empty pipe until data is available, and block when they write to a full pipe until there is space available. Like message queues, ISRs can write to a pipe, but cannot read from a pipe.
As I/O devices, pipes provide one important feature that message queues cannot--the ability to be used with select( ). This routine allows a task to wait for data to be available on any of a set of I/O devices. The select( ) routine also works with other asynchronous I/O devices including network sockets and serial devices. Thus, by using select( ), a task can wait for data on a combination of several pipes, sockets, and serial devices; see 3.3.8 Pending on Multiple File Descriptors: The Select Facility.
Pipes allow you to implement a client-server model of intertask communications; see Servers and Clients with Message Queues.
In VxWorks, the basis of intertask communications across the network is sockets. A socket is an endpoint for communications between tasks; data is sent from one socket to another. When you create a socket, you specify the Internet communications protocol that is to transmit the data. VxWorks supports the Internet protocols TCP and UDP. VxWorks socket facilities are source compatible with BSD 4.4 UNIX.
TCP provides reliable, guaranteed, two-way transmission of data with stream sockets. In a stream-socket communication, two sockets are "connected," allowing a reliable byte-stream to flow between them in each direction as in a circuit. For this reason TCP is often referred to as a virtual circuit protocol.
UDP provides a simpler but less robust form of communication. In UDP communications, data is sent between sockets in separate, unconnected, individually addressed packets called datagrams. A process creates a datagram socket and binds it to a particular port. There is no notion of a UDP "connection." Any UDP socket, on any host in the network, can send messages to any other UDP socket by specifying its Internet address and port number.
One of the biggest advantages of socket communications is that it is "homogeneous." Socket communications among processes are exactly the same regardless of the location of the processes in the network, or the operating system under which they are running. Processes can communicate within a single CPU, across a backplane, across an Ethernet, or across any connected combination of networks. Socket communications can occur between VxWorks tasks and host system processes in any combination. In all cases, the communications look identical to the application, except, of course, for their speed.
For more information, see VxWorks Network Programmer's Guide: Networking APIs and the reference entry for sockLib.
Remote Procedure Calls (RPC) is a facility that allows a process on one machine to call a procedure that is executed by another process on either the same machine or a remote machine. Internally, RPC uses sockets as the underlying communication mechanism. Thus with RPC, VxWorks tasks and host system processes can invoke routines that execute on other VxWorks or host machines, in any combination.
As discussed in the previous sections on message queues and pipes, many real-time systems are structured with a client-server model of tasks. In this model, client tasks request services of server tasks, and then wait for their reply. RPC formalizes this model and provides a standard protocol for passing requests and returning replies. Also, RPC includes tools to help generate the client interface routines and the server skeleton.
For more information on RPC, see VxWorks Network Programmer's Guide: RPC, Remote Procedure Calls.
VxWorks supports a software signal facility. Signals asynchronously alter the control flow of a task. Any task or ISR can raise a signal for a particular task. The task being signaled immediately suspends its current thread of execution and executes the task-specified signal handler routine the next time it is scheduled to run. The signal handler executes in the receiving task's context and makes use of that task's stack. The signal handler is invoked even if the task is blocked.
Signals are more appropriate for error and exception handling than as a general-purpose intertask communication mechanism. In general, signal handlers should be treated like ISRs; no routine should be called from a signal handler that might cause the handler to block. Because signals are asynchronous, it is difficult to predict which resources might be unavailable when a particular signal is raised. To be perfectly safe, call only those routines that can safely be called from an ISR (see Table 2-23). Deviate from this practice only when you are sure your signal handler can not create a deadlock situation.
The wind kernel supports two types of signal interface: UNIX BSD-style signals and POSIX-compatible signals. The POSIX-compatible signal interface, in turn, includes both the fundamental signaling interface specified in the POSIX standard 1003.1, and the queued-signals extension from POSIX 1003.1b. For the sake of simplicity, we recommend that you use only one interface type in a given application, rather than mixing routines from different interfaces.
For more information on signals, see the reference entry for sigLib.
Table 2-20 shows the basic signal routines. To make these facilities available, the signal library initialization routine sigInit( ) must be called, normally from usrInit( ) in usrConfig.c, before interrupts are enabled.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The colorful name kill( )harks back to the origin of these interfaces in UNIX BSD. Although the interfaces vary, the functionality of BSD-style signals and basic POSIX signals is similar.
In many ways, signals are analogous to hardware interrupts. The basic signal facility provides a set of 31 distinct signals. A signal handler binds to a particular signal with sigvec( ) or sigaction( ) in much the same way that an ISR is connected to an interrupt vector with intConnect( ). A signal can be asserted by calling kill( ). This is analogous to the occurrence of an interrupt. The routines sigsetmask( ) and sigblock( ) or sigprocmask( ) let signals be selectively inhibited.
Certain signals are associated with hardware exceptions. For example, bus errors, illegal instructions, and floating-point exceptions raise specific signals.
The sigqueue( ) routine provides an alternative to kill( ) for sending signals to a task. The important differences between the two are:
VxWorks includes seven signals reserved for application use, numbered consecutively from SIGRTMIN. The presence of these reserved signals is required by POSIX 1003.1b, but the specific signal values are not; for portability, specify these signals as offsets from SIGRTMIN (for example, write SIGRTMIN+2 to refer to the third reserved signal number). All signals delivered with sigqueue( )are queued by numeric order, with lower-numbered signals queuing ahead of higher-numbered signals.
POSIX 1003.1b also introduced an alternative means of receiving signals. The routine sigwaitinfo( )differs from sigsuspend( )or pause( )in that it allows your application to respond to a signal without going through the mechanism of a registered signal handler: when a signal is available, sigwaitinfo( ) returns the value of that signal as a result, and does not invoke a signal handler even if one is registered. The routine sigtimedwait( )is similar, except that it can time out.
For detailed information on signals, see the reference entry for sigLib.
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
|
|
|||||||||||||||||||
The basic signal facility is included in VxWorks by default with INCLUDE_SIGNALS (located under kernel components in the project facility).
Before your application can use POSIX queued signals, they must be initialized separately with sigqueueInit( ). Like the basic signals initialization function sigInit( ), this function is normally called from usrInit( ) in usrConfig.c, after sysInit( ) runs.
To initialize the queued signal functionality, also define INCLUDE_POSIX_SIGNALS (located under POSIX components in the project facility): with that definition, sigqueueInit( ) is called automatically.
The routine sigqueueInit( ) allocates nQueues buffers for use by sigqueue( ), which requires a buffer for each currently queued signal (see the reference entry for sigqueueInit( )). A call to sigqueue( ) fails if no buffer is available.
1: Some host operating systems, such as UNIX, require symbolic names for objects that are to be shared among processes. This is because processes do not normally share memory in such operating systems. In VxWorks, there is no requirement for named semaphores, because all objects are located within a single address space, and reference to shared objects by memory location is standard practice.
2: This is not a POSIX routine, nor is it designed for use from programs; use it from the Tornado shell (see the Tornado User's Guide: Shell for details).
3: However, to get information on POSIX message queues, INCLUDE_POSIX_MQ_SHOW must be defined in the VxWorks configuration; for information, see Tornado User's Guide: Projects.
4: The built-in show( ) routine handles Wind message queues; see the Tornado User's Guide: Shell for information on built-in routines. You can also use the Tornado browser to get information on Wind message queues; see the Tornado User's Guide: Browser for details.
![]()
![]()
![]()
![]()
![]()